Qi-Jun Hong About Me Twitter CDC
Last updated: May 15, 2022 (Next update: no earlier than Jun 15)
Previous Projections: May25 May29 Jun02 Jun04 Jun05 Jun08 Jun15 Jun19 Jun22 Jun25 Jun29 Jul03 Jul06 Jul10 Jul13 Jul16 Jul20 Jul23 Jul27 Jul31 Aug05 Aug10 Aug17 Aug25 Aug31 Sep10 Sep15 Sep23 Sep28 Oct05 Oct12 Oct20 Oct26 Nov02 Nov06 Nov09 Nov12 Nov16 Nov19 Nov23 Nov30 Dec07 Dec14 Dec21 Dec28 Jan11 Jan19 Jan31 Feb20 Jul12 Jul19 Aug02 Aug15 Aug29 Sep12 Sep26 Oct10 Nov04 Nov18 Dec16 Dec30 Jan13 Jan27 Feb12
This is a personal project and these are my own views.

Covid19 Encounter Model by Qi-Jun Hong is licensed under a Creative Commons Attribution 4.0 International License.
Based on a work at https://github.com/qjhong/covid19.
Projection summary
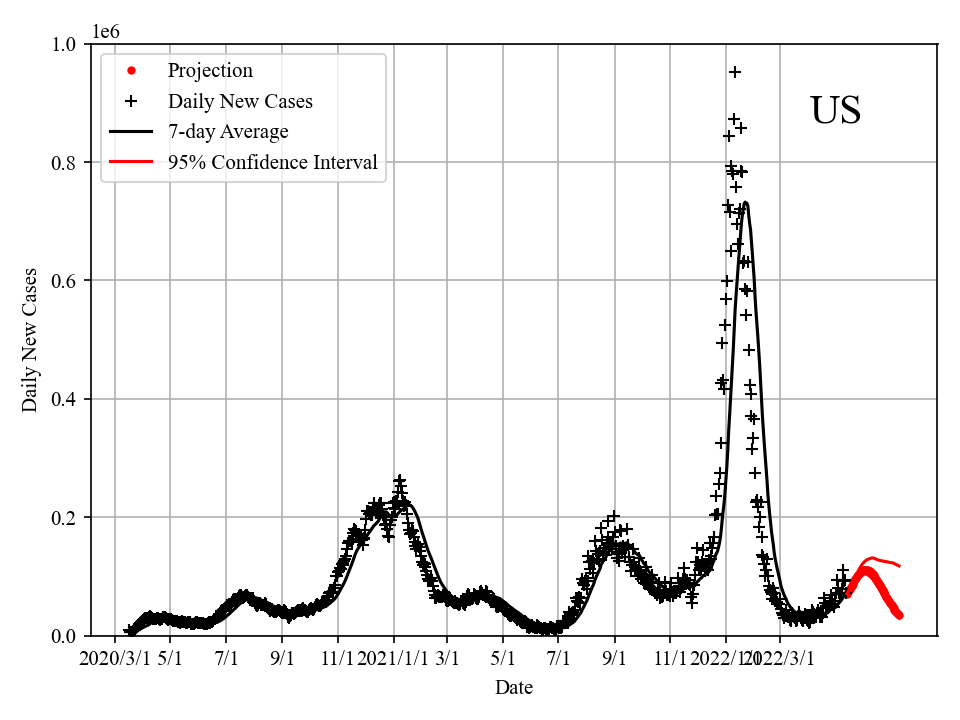
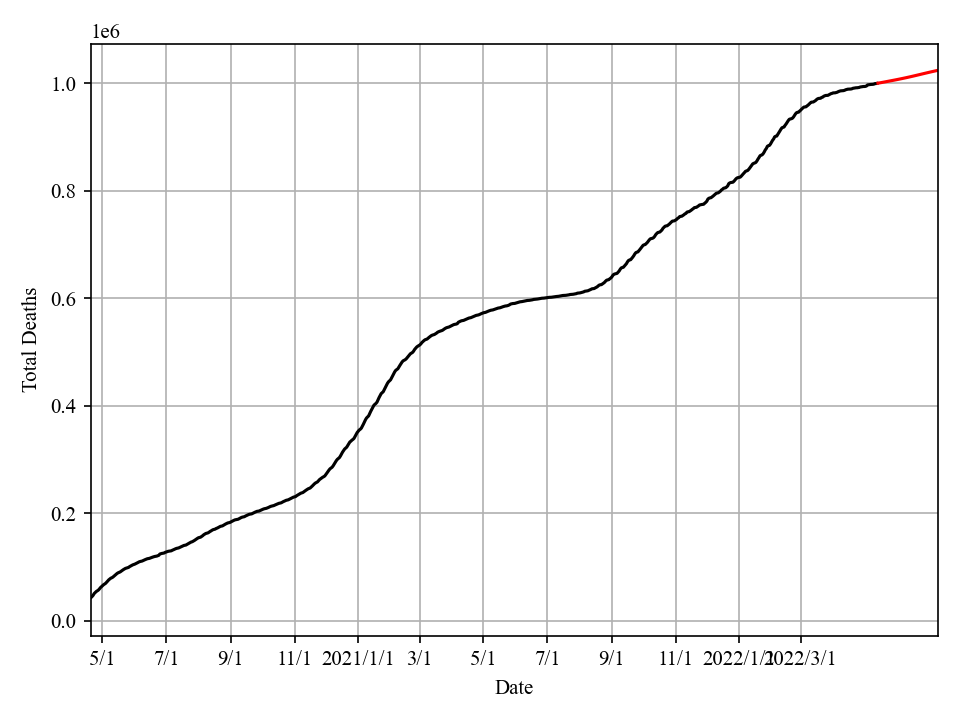
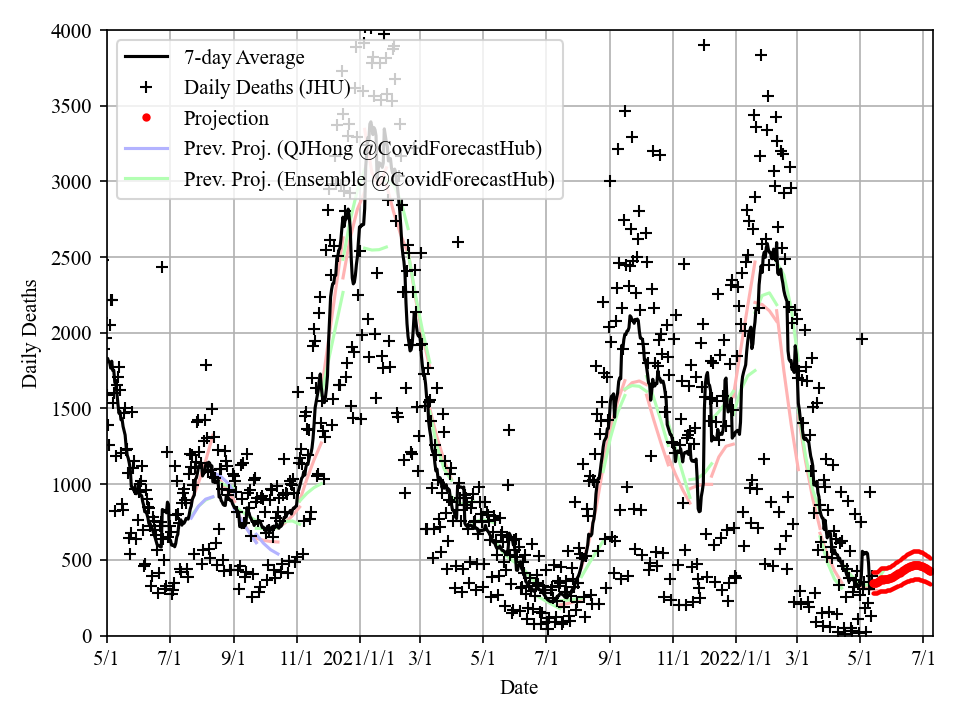
- May 15: The US fatality is reaching the 1,000,000 mark this week. There is another wave coming, but it will not be severe, with high vaccination rate and low fatality rate of Omicron.
- Feb 12: The fatality curve is peaking. The US has surpassed 900,000 total deaths. We might be able to avoid the 1,000,000 mark, but it depends on many factors.
- Jan 27: Now I have sufficient data to make reliable projections. The case curve has already peaked, while fatality curve will peak slightly below 3000 / day. The US will surpass 900,000 total deaths on Feb 7, and the 1,000,000 mark on March 19.
- Jan 13 2022: It is still very hard to make reliable projections. As more Omicron data comes in, the model is starting to learn from it. A significant increase in fatality is inevitable.
- Dec 30 2021: Reproductive number and positivity ratio are at record high. The new Omicron variant poses a great challenge for machine learning, because there is little data to learn from. The case curve forecast is terrible for the coming weeks. The fatality curve is probably overestimated.
- Dec 16: The impact from the Omicron variant is still unclear. Vaccination protects the US from severe surge in cases and deaths. The US is expected to surpass 900,000 total deaths in Feb.
- Nov 18: The US will surpass 800,000 total deaths on Dec 18, and 900,000 around end of Feb.
- Nov 04: There will be another wave this winter. The US will surpass 800,000 total deaths by year end.
- Oct 10: The fatality curve has already peaked. The US will surpass 750,000 total deaths on Nov 7, and 800,000 by year end.
- Sep 26: Daily cases have already peaked. The fatality curve will peak in one week. The US will surpass 700,000 total deaths on Oct 2.
- Sep 12: Daily cases have already peaked. The fatality curve will peak near end of Sept, with around 2,000 deaths per day. The US will surpass 700,000 total deaths on Oct 5.
- Aug 29: This wave will peak near end of Sept, with around 2,000 deaths per day.
- Aug 15: There are early signs that the curve is flattened.
- Aug 02: Daily fatality count will rise rapidly in August. It will surpass 1,000/day.
- Jul 19: This wave could be worse than the previous one.
- Jul 12: It appears more and more likely that there will be another wave due to the Delta variant.
- Feb 20: My model projects rapid decrease of cases and deaths over the next few weeks in the US.
- Feb 20: Fatality will cross below 2000 deaths/day by end of Feb, and 1000 deaths/day by end of March.
- Feb 20: Total Deaths will reach 500,000 by Feb 23. Total Deaths will not be higher than 600,000 when the pandemic ends.
- Feb 01: My model projects stable decrease of cases over the next few weeks in the US. Fatality has peaked, but its decline will be slow. Averaged daily deaths will not cross below 2,000/day until March.
- Jan 19: Fatality will peak in early February. The peak is at 3000-3500 deaths/day, with single day max above 4000.
States at risk:
Next 30 days
Projection of the Next 60 Days
State Projection:
AK AL AR AZ CA CO CT DC DE FL GA HI IA ID IL IN KS KY LA MA MD ME MI MN MO MS MT NC ND NE NH NJ NM NV NY OH OK OR PA RI SC SD TN TX US UT VA VT WA WI WV WY
Daily new confirmed cases:
Total deaths:
Daily deaths:
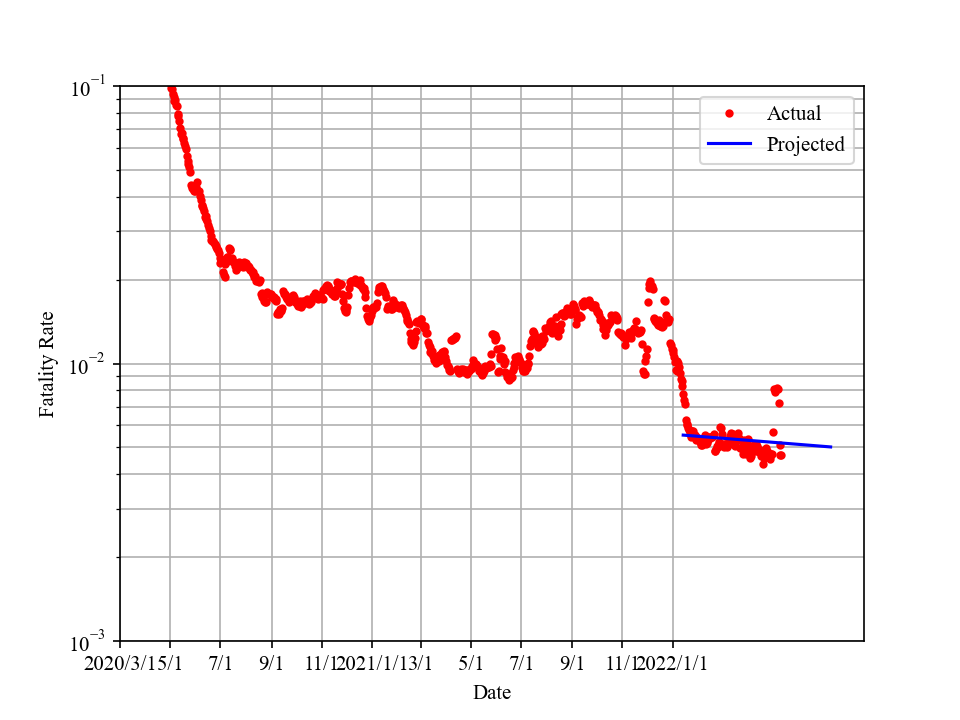
Fatality rate Poisson weighted:
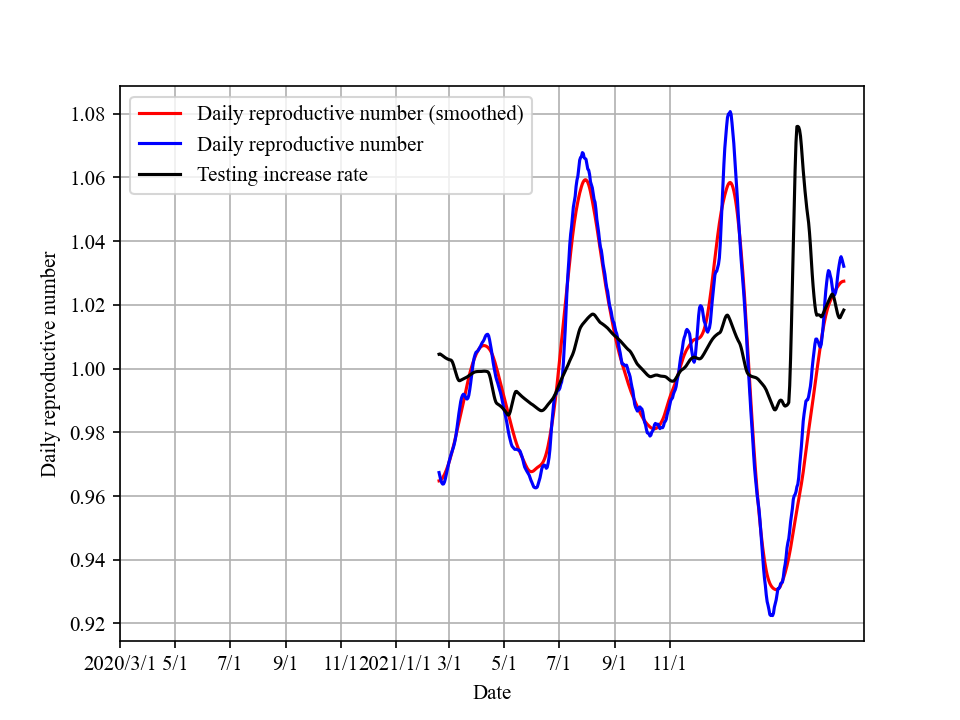
Reproductive number:
My Model’s Ranking by Youyang Gu:
On Nov 2, Youyang Gu slightly changed his ranking method. For transparency, I keep ranking results both before and after the change. (See Nov 02 link at top of page)
If we compare median/mean ranking, my model is at the top of the list, regardless of the change.
Starting the next update, I will post ranking only using the new method (since this is Youyang Gu’s ranking evaluation).
Weekly ranking, 1-6w forward performance
![]()
Overall ranking and RMSE/MAE of errors
![]()
Daily Tests and Daily New Cases
(Data source: the COVID Tracking Project)
What is the idea?
UPDATE: Since Oct 12, my model has included more features, in addition to encounter density. XGBoost is employed for regression.
today's "Daily New Confirmed Cases" + today's "Encounter Density" ==> today's newly infected Cases ==> next 2-3 weeks' "Daily New Confirmed Cases"
(Encounter Density D data source: Unacast's Social Distancing Scoreboard, which analyzes cell phone location data, counts "Human Encounters", defined as two cell phone devices that were in the same place at the same time, and then derives the probability and "Encounter Density".)
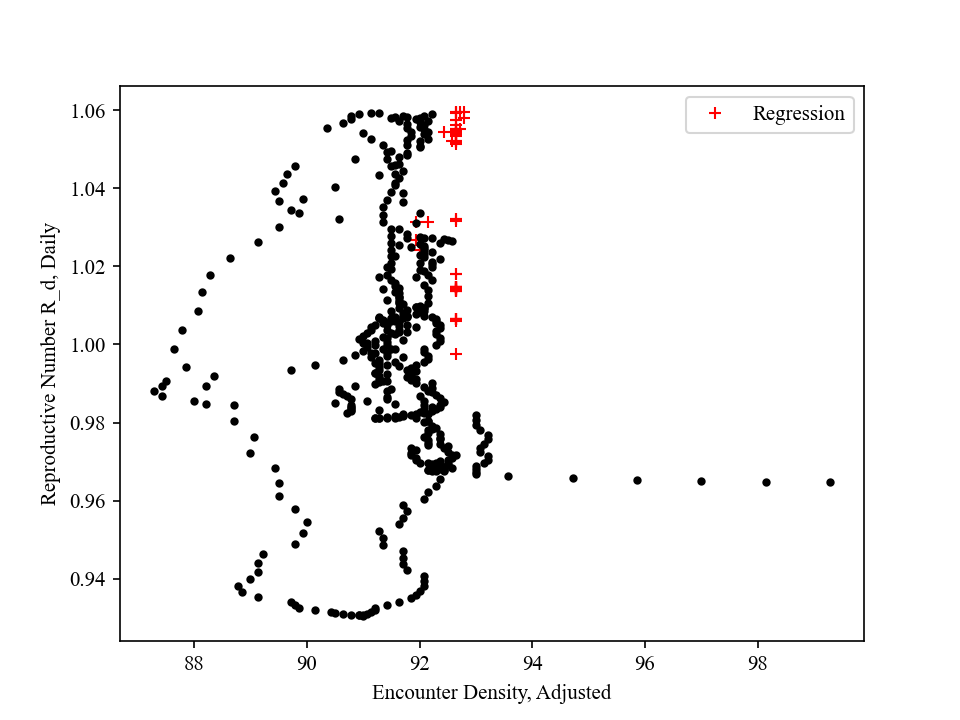
My model uses current "Encounter Density" D to predict future "Reproductive Number" R and "Daily New Confirmed Cases". This is the most fundamental idea and assumption in this model.
Why "Encounter" data?
Daily New Confirmed Cases data is "outdated". People who get confirmed today were infected days ago through "Human Encounter" with other contagious people, and it took days to develop symptoms, seek tests, and get confirmed (infected -> symptomatic -> tested -> confirmed). In other words, today's "Daily New Confirmed Cases" is outdated data and it can be inferred from past "Daily New Confirmed Cases" data + past "Encounter" data.
Encounter data is up-to-date. Typically yesterday's Human Encounter Density data is available online today. (Encounter Density D data source: Unacast's Social Distancing Scoreboard, which analyzes cell phone location data, counts "Human Encounters", defined as two cell phone devices that were in the same place at the same time, and then derives the probability and "Encounter Density".)
How does it work?
The strong correlation between R and D (D is shifted by ~22 days) is evident in this figure. While social distancing quickly brought down R, easing policy is slowly increasing R back above 1.
Using (1) R and D relation in the past as a training set, (2) future D as input, and (3) machine learning / regression, my model can predict future R, and ultimately future Daily New Cases.
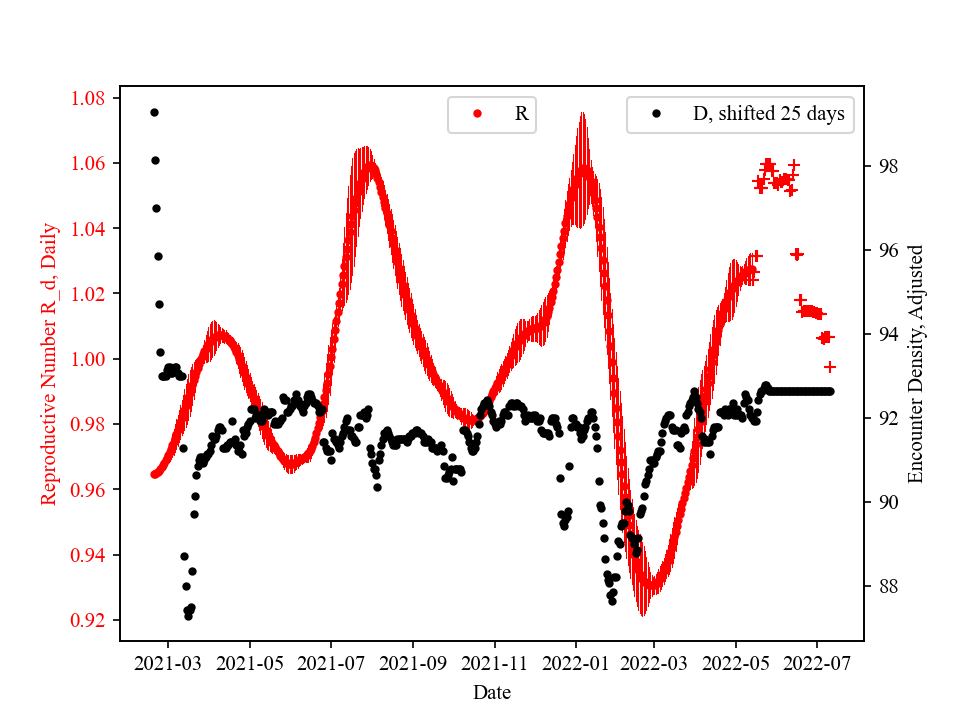
Shown in red is "Daily Reproductive Number" R_d, which is obtained through fitting of existing "Daily New Confirmed Cases". By definition, if day 1 daily new cases in N, day 2 number will be N*R_d. Hence, the ultimate goal is to keep R_d under 1.
The black dots are Adjusted Encounter Density D_adj, shifted forward by ~22 days. These two curves are remarkably close. For example, R started to quickly decrease at around 3/20. This coincides with a sudden decrease of D at the end of Feb, ~20 days before. R reached bottom at ~4/15 and stayed at the level till ~5/15. This overlaps with low D between 3/20 to 4/20. The amount of shift is optimized to maximize overlap, and the value is determined as ~22 days. The values are normalized to pre-pandamic levels, so 1.0 means activity level before pandemic hit US.